In the Sunday Morning Insight on a Quick Panorama of Sensing from Direct Imaging to Machine Learning, I pointed out to the continuous spectrum of ideas that went from 'pure' sensing all the way to the current machine learning techniques. In fact some of the indirect imaging (compressive sensing) could fit well into machine learning approaches with various instances of nonlinear compressive sensing, in particular quantization and 1bit CS [7]. Now the question that immediately arises after this parallel is: are there sharp phase transitions in Machine Learning as those found in compressive sensing and advanced matrix factorization. In these fields, these sharp phase transitions have been found to be pretty universal and they really divide what is computable with a polynomail algorithm (P) and what is not currently known to have a polynomial algorithm (NP) ( see Sunday Morning Insight's (The Map Makers)). It turns out that any advances in compressive sensing can really only be gauged with how one can push these boundaries ( see "...This result is quite striking...." ). Do we see these phase transitions in machine learning algorithms ?
While reading some of the NIPS2013 papers, I just stumbled upon this preprint [0] (Knowledge Matters: Importance of Prior Information for Optimization by Çağlar Gülçehre, Yoshua Bengio) that asks the question as to whether any of the current approaches in Machine Learning have this ability to do well on simple benchmarks. The idea being that unlike most datasets against which most machine learning algorithms are comparing themselves, eventually, there is a sense that a simpler 'dataset' might provide some insight. From the abstract , the challenge is

In our experiments, a two-tiered MLP architecture is trained on a dataset with 64x64 binary inputs images, each image with three sprites. The final task is to decide whether all the sprites are the same or one of them is different. Sprites are pentomino tetris shapes and they are placed in an image with different locations using scaling and rotation transformations.
This is indeed a simple benchmark that has the added property of being very sparse even for image processing tasks. We also all realize that we are comparing two beasts. In ML parlance, the CS approach has a linear layer and a nonlinear one, while a traditional neural network, for instance, has only nonlinear layers. From the paper, one can read the following interesting bits:
Interestingly, the task we used in our experiments is not only hard for deep neural networks but also for non-parametric machine learning algorithms such as SVM's, boosting and decision trees.
....the task in the first part is to recognize and locate each Pentomino object class6 in the image. The second part/fi nal binary classi cation task is to fi gure out if all the Pentominos in the image are of the same shape class or not. If a neural network learned to detect the categories of each object at each location in an image, the remaining task becomes an XOR-like operation between the detected object categories........With 40,000 examples, this gives 32,000 examples for training and 8,000 examples for testing. For neural network algorithms, stochastic gradient descent (SGD) is used for training. The following standard learning algorithms were rst evaluated: decision trees, SVMs with Gaussian kernel, ordinary fully-connected Multi-Layer Perceptrons, Random Forests, k-Nearest Neighbors, Convolutional Neural Networks, and Stacked Denoising Auto-Encoders with supervised ne-tuning....
and from the conclusion
The task has the particularity that it is de ned by the composition of two non linear sub-tasks (object detection on one hand, and a non-linear logical operation similar to XOR on the other hand).What is interesting is that in the case of the neural network, we can compare two networks with exactly the same architecture but a different pre-training, one of which uses the known intermediate concepts to teach an intermediate representation to the network. With enough capacity and training time they can overfit but did not not capture the essence of the task, as seen by test set performance.We know that a structured deep network can learn the task, if it is initialized in the right place, and do it from very few training examples. Furthermore we have shown that if one pre-trains SMLP with hints for only one epoch, it can nail the task. But the exactly same architecture which started training from random initialization, failed to generalize.
But here is what caught my attention, figure 12.. and many others actually:
Most ML practitionners will recognize that past a certain number of training elements, the algorithm has learned the identity. But we ought to look at it from the point of view of what we know in linear systems, i.e compressive sensing and related matrix factorization techniques.
In essence in this training items are fed in order to build a model and it hits a region where the function being modeled reproduces well the identity. A similar phase transition [2,6] can be found in the equivalent problem found in blind compressive sensing [1,4,5] (some of this work is currently being presented at NIPS2013) or blind deconvolution where one feeds a linear model with sparse objects and finds the ability to reconstruct the whole linear operator after a certain number of 'training' elements.
In essence in this training items are fed in order to build a model and it hits a region where the function being modeled reproduces well the identity. A similar phase transition [2,6] can be found in the equivalent problem found in blind compressive sensing [1,4,5] (some of this work is currently being presented at NIPS2013) or blind deconvolution where one feeds a linear model with sparse objects and finds the ability to reconstruct the whole linear operator after a certain number of 'training' elements.
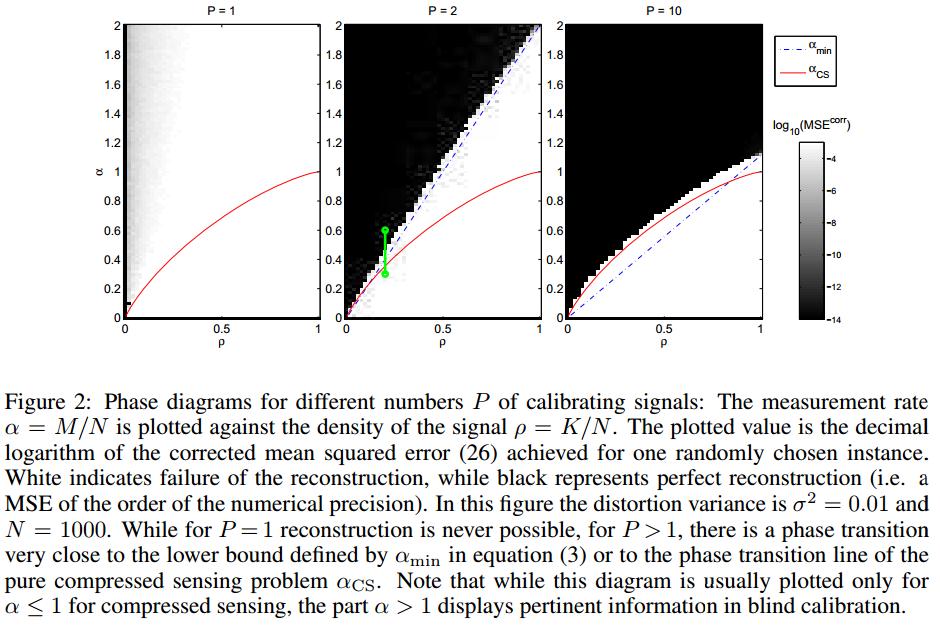
From [1]

From [5]

From [8]
[0] Knowledge Matters: Importance of Prior Information for Optimization by Çağlar Gülçehre, Yoshua Bengio
We explore the effect of introducing prior information into the intermediate level of neural networks for a learning task on which all the state-of-the-art machine learning algorithms tested failed to learn. We motivate our work from the hypothesis that humans learn such intermediate concepts from other individuals via a form of supervision or guidance using a curriculum. The experiments we have conducted provide positive evidence in favor of this hypothesis. In our experiments, a two-tiered MLP architecture is trained on a dataset with 64x64 binary inputs images, each image with three sprites. The final task is to decide whether all the sprites are the same or one of them is different. Sprites are pentomino tetris shapes and they are placed in an image with different locations using scaling and rotation transformations. The first part of the two-tiered MLP is pre-trained with intermediate-level targets being the presence of sprites at each location, while the second part takes the output of the first part as input and predicts the final task's target binary event. The two-tiered MLP architecture, with a few tens of thousand examples, was able to learn the task perfectly, whereas all other algorithms (include unsupervised pre-training, but also traditional algorithms like SVMs, decision trees and boosting) all perform no better than chance. We hypothesize that the optimization difficulty involved when the intermediate pre-training is not performed is due to the {\em composition} of two highly non-linear tasks. Our findings are also consistent with hypotheses on cultural learning inspired by the observations of optimization problems with deep learning, presumably because of effective local minima.
The code to reproduce the figures in this paper can be found here:
[1] Blind Calibration in Compressed Sensing using Message Passing Algorithms by Christophe Schülke, Francesco Caltagirone, Florent Krzakala,Lenka Zdeborová also at NIPS2013
[7] Entries on Nuit Blanche related to 1-bit compressive sensing and those related to Quantisied compressive sensing.
 Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
Liked this entry ? subscribe to Nuit Blanche's feed, there's more where that came from. You can also subscribe to Nuit Blanche by Email, explore the Big Picture in Compressive Sensing or the Matrix Factorization Jungle and join the conversations on compressive sensing, advanced matrix factorization and calibration issues on Linkedin.
No comments:
Post a Comment